字符編碼詳解及利用C++STLstring遍歷中文字符串-創新互聯
C++遍歷英文字符串作者:非妃是公主
成都創新互聯公司主營華安網站建設的網絡公司,主營網站建設方案,app開發定制,華安h5小程序制作搭建,華安網站營銷推廣歡迎華安等地區企業咨詢
專欄:《筆記》《C++》
個性簽:順境不惰,逆境不餒,以心制境,萬事可成。——曾國藩文章目錄
- C++遍歷英文字符串
- C++遍歷中文字符串(不會出問題情況)
- C++遍歷中文字符串(會出現問題的情況)
- 英文字符的表示
- 中文字符的表示
- 定長編碼
- 變長編碼
- Unicode編碼
- 正確的中文字符串遍歷方式
- 參考資料

C++遍歷英文字符串很簡單,基本有兩種方法
// 方法1
for(int i=0; i< str.size(); i++){cout<< str[i];
}
// 方法2
for(auto it = str.begin(); it != str.end(); it++){cout<< *it;
}以上兩種方法基本就可以很好地遍歷英文字符串了!
C++遍歷中文字符串(不會出問題情況)但是中文字符串呢?我們來試一下:
發現是可以正常輸出的!
再繼續試!這次這樣嘗試,因為我們遍歷字符串一般都是要對字符串中的字符進行操作,如果單純只是輸出或者顯示而已,沒必要去遍歷字符,直接cout<
這次添加了一個if (str[i] == '非') continue;的判斷,但是‘非’依然輸出了出來。
調試一下:
i = 0,但是str[i] == '非'確實false,這是怎么回事呢?
我們知道,遍歷字符串主要就是要對字符串進行操作,可是如今字符串判斷相等卻出現了問題……
這里給出測試代碼,感興趣的老哥可以自己去調試:
void test1() {string str = "非妃是公主";
cout<< "這時test1:";
for (int i = 0; i< str.size(); i++) {
if (str[i] == '非') continue;
cout<< str[i];
}
cout<< endl;
}
void test2() {string str = "非妃是公主";
cout<< "這時test2:";
for (auto it = str.begin(); it != str.end(); it++) {cout<< *it;
}
cout<< endl;
}
int main() {test1();
test2();
}其實,這里涉及到了一個編碼的問題,ASCII碼值是一個字符集表,里面編碼了26個英文字母的大小寫(大寫字母65~90,小寫字母97~120),還有其它英文字符(比如空格、單引號……),其中有一些甚至是不可顯示的(比如換行符、分組符……)。具體可以查看ASCII碼表.
利用ASCII(美國信息交換標準代碼)就可以實現英文的字符映射了,因為英文字母只有那么些,所有的單詞都是根據這些字母進行排列組合形成的。
下面為ASCII碼表的節選(開頭和結尾部分):

可以看到,從0~127,ASCII碼表有128個編碼,而
2
8
=
256
2^8=256
28=256,也就是說可以用1個字節(Byte,等于8個bit)大小的內存空間來編碼所有的英文字符,因此char利用這樣的字節編碼到字符進行映射就可以實現英文字符串的運算。
從上面不難看出,英文可以利用一個很小的字符集(ASCII——美國信息交換標準代碼)去表示所有單詞(因為只有26個字母等優先的符號),但中文不可以,中華漢字博大精深,其中包含了幾千甚至上萬的漢字(如果還包括一些繁體字、生僻字等數量會更大)!
因此,1個Byte不能滿足中文編碼的需要,我們需要2個、3個甚至4個Byte進行編碼才能把中文表示出來!
這里就包含了兩種編碼的方式,定長編碼和變長編碼。
定長編碼定長編碼:顧名思義,就是每個字符對應的編碼的長度都是相等的,這里不得不提到GB2312編碼和GBK編碼。
- GB2312編碼:就是把漢字編碼成兩個字節,一個字節有 2 8 = 256 2^8=256 28=256種不同的編碼,兩個字節就有 2 16 = 65536 2^{16}=65536 216=65536種不同的編碼,也就是說我們最多可以編碼65536種情況,這些對于常用的文字應該可以了吧……但是,值得一提的是,GB2312并沒有使用完全這些編碼,它只用了一部分,那么剩下的呢?GB2312為了保持向下兼容ASCII,它避免了和ASCII進行沖突編碼,這要浪費一部分編碼空間,但依然還是有空余的,這些空余下的位置暫且留著,GB2312沒有使用!
- GBK編碼:和 GB2312 一樣,GBK 也是雙字節編碼,同樣為了向下兼容 GB2312, GBK使用了GB2312 沒有用到的那些編碼區域,簡單地說,就是進一步拓展了編碼集,GBK比GB2312編碼了更多的漢字。
可以說,GBK編碼是對GB2312編碼的補充!
關于定長編碼的詳細規則可以在這篇文章里看到,總結的十分全面https://zhuanlan.zhihu.com/p/453675608
變長編碼變長編碼:是一種包含多個長度編碼的字節結構!換句話說,這種類型的編碼既可以使用1個字節,也可以使用2個字節,3個字節,以及4個字節,那么就來了一個問題,我怎么知道這個編碼到底是用了幾個字節呢?到底是1個字節,2個字節還是3個、4個字節呢?也就是如何進行解析呢?
這里,以GB18030編碼為例進行說明,它也是一種變長編碼,有1個字節,2個字節以及4個字節大小的編碼,下圖為GB18030編碼的字節結構示意圖:
從圖中可以很容易地看出:
- 前8位為00-80大小的,只有一個字節
- 前8位為81-FE,9~16位位40-FE的有兩個字節,基本就是兼容GBK編碼(但是和GBK還是有區別的,詳細區別讀者可以自行查閱)
- 前8位位81-84,9-16位為30-39的,17-24位為81-FE的,25-32位為30-39的有4個字節!
- ……
- 根據表格,按照上述的字節區間編碼結構就可以進行解碼了。
4個字節可以表示更多的字符。
其實GB是國標的意思:
國家標準GB18030-2000《信息交換用漢字編碼字符集基本集的補充》是我國繼GB2312-1980和GB13000-1993之后最重要的漢字編碼標準,是我國計算機系統必須遵循的基礎性標準之一。
GB18030-2000編碼標準是由信息產業部和國家質量技術監督局在2000年3月17日聯合發布的,并且將作為一項國家標準在2001年的1月正式強制執行。 GB18030-2005《信息技術中文編碼字符集》是我國制訂的以漢字為主并包含多種我國少數民族文字(如藏、蒙古、傣、彝、朝鮮、維吾爾文等)的超大型中文編碼字符集強制性標準,其中收入漢字70000余個。
也就是說,這一個標準是我國制定的,并沒有在國際上通用!它只編碼了我國的漢字以及少數名族文字等。
Unicode編碼Unicode 其實是一個字符集,這個字符集給世界上常用的字符都進行了編碼,每一個字符對應一個唯一的編碼。但值得注意的是,它并不是一個字符編碼,Unicode還需要依靠一些字符編碼規范,才能發揮作用,后面會提到。Unicode 字符集的編碼范圍是0x0000 - 0x10FFFF,相比于上面提到的字符編碼標準(帶GB的都是國標的漢語拼音首字母,因此都是國內的標準),Unicode是一個國際化的標準。換句話說,如果說GB2312、GBK、GB18030是國家級的字符編碼,那么Unicode就是一個國際級的字符集!
從上面提到的Unicode的范圍可以看出,如果直接編碼,我們只需要三個字符就可以編碼它。但是,比如第1個字符,如果用3個Byte進行編碼,那么它的編碼應該是0x000001,問題來了,前面的0并沒有包含什么信息,本來1個字節可以存儲的,卻消耗了3個字節,這是一種存儲空間,以及計算機效率的浪費!
因此這里同樣采用邊長編碼,這也就解釋了上面為什么Unicode是字符集,而不是一種字符編碼了,因為如果直接使用它進行編碼會浪費大量的空間和時間。
Unicode的編碼規則對應utf-8、utf-16、utf-32,每個都代表一種不同的編碼規則,utf是Unicode transform format的縮寫,Unicode變換格式的縮寫。
- utf-8編碼:是一種邊長編碼規則,可以使用1~4個字節,具體地說:
- 對于單字節的符號,字節的第一位設為 0,后面 7 位為這個符號的 Unicode 碼。因此對于英語字母,UTF-8 編碼和 ASCII 碼是相同的, 所以 UTF-8 能兼容 ASCII 編碼,這也是互聯網普遍采用 UTF-8 的原因之一。
- 對于 n 字節的符號( n >1),第一個字節的前 n 位都設為 1,第 n + 1 位設為 0,后面字節的前兩位一律設為 10 。剩下的沒有提及的二進制位,全部為這個符號的 Unicode 碼。
- 那么緊接著就有一個問題,沒有占滿怎么半,答案是補0,從右往左占,高位占不滿的自動補0。
- 還有1個問題,不夠位數怎么半,這個問題好解決,增加字節就是了。4個字節最多可以表示
3+6+6+6=21,仔細想一下,剛好覆蓋Unicode 字符集的編碼范圍是0x0000 - 0x10FFFF,沒有任何問題。
- utf16編碼:它也是一種變長編碼規則,但是它將字符編碼成2字節或者4字節。
- 對于 Unicode 碼小于 0x10000 的字符, 使用 2 個字節存儲,并且是直接存儲 Unicode 碼,不用進行編碼轉換;
- 對于 Unicode 碼在 0x10000 和 0x10FFFF 之間的字符,使用 4 個字節存儲,這 4 個字節分成前后兩部分,每個部分各兩個字節,其中,前面兩個字節的前 6 位二進制固定為 110110,后面兩個字節的前 6 位二進制固定為 110111, 前后部分各剩余 10 位二進制表示符號的 Unicode 碼 減去 0x10000 的結果。20位bit正好可以表示0xFFFF。
- 大于 0x10FFFF 的 Unicode 碼無法用 UTF-16 編碼。
- utf-32編碼:UTF-32 是固定長度的編碼,始終占用 4 個字節,足以容納所有的 Unicode 字符,所以直接存儲 Unicode 碼即可,不需要任何編碼轉換。雖然浪費了空間,但提高了效率。

從圖中可以看到非妃是公主5個字的漢字字符,但是,無論size和length都是10,這說明:length()和size()返回的并不是字符串的長度,而是字符串占用了多少個Byte。
進一步推測:s[i]指的是第i個Byte,it++也指的是前進1個Byte。
而GBK和GB13080都對GB2312向下兼容,而GB2312就包含了漢字中絕大多數,部分生僻字和繁體字是不包含的,GB2312是用2個字節進行表示的。
因此,這里i和i+1才能表示1個字符。
而2個Byte就不能用char(1個Byte)來表示了,string底層是由char實現的,而漢字至少包含兩個char的大小,所以要繼續用string來表示一個漢字:
遍歷算法應該如下:
void test3() {string str = "非妃是公主";
cout<< "這時test3:";
for (int i = 0; i< str.size(); i = i + 2) {string tmp = "";
tmp = tmp + str[i] + str[i + 1];
if (tmp == "非") continue;
cout<< tmp;
}
cout<< endl;
}執行結果如下:
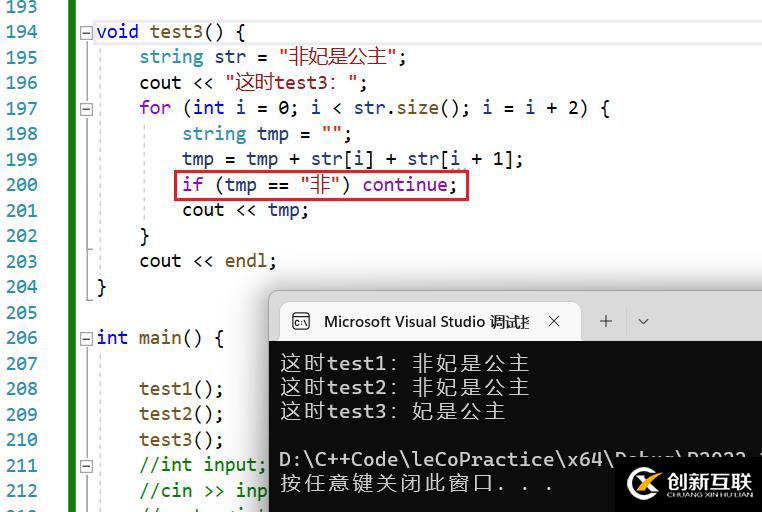
從輸出結果中可以看出if (tmp == "非") continue;已經被執行了。
同時,經過調試可以發現,因為字符串的==運算符應該是經過重載生成的,所以在調試時顯示沒有與操作數匹配的“==”運算符,無法進行監視。
但是從圖中可以看出,tmp的值已經是“非”了。也實現了預期的結果,進而可以實現字符串遍歷中對單個中文字符串的操作。

同時也在交流群里向大佬交流了一下,大佬幫忙給找了一個參考代碼,此處一并貼出,并已標明出處[5],我在這里加上注釋,對代碼進行解釋,如下:
string text = "今天周五123";
for(size_t i = 0; i< text.length();)
{int cplen = 1;
if((text[i] & 0xf8) == 0xf0) cplen = 4; // 占用4個字節,前5位為11110
else if((text[i] & 0xf0) == 0xe0) cplen = 3; // 占用3個字節,前4位為1110
else if((text[i] & 0xe0) == 0xc0) cplen = 2; // 占用2個字節,前3位為110
// 個人感覺這行代碼好像沒什么用,如果三種情況都不符合,那么cplen就為初始化的0,是符合utf-8編碼定義的
if((i + cplen) >text.length()) cplen = 1;
cout<< text.substr(i, cplen)<< endl;
i += cplen;
}其實2個Byte基本已經可以表示大多數中文了,除了極少的繁體字和生僻字,但是上面的代碼包含了3個Byte和4個Byte的情況,感嘆大佬的代碼確實更加完善!
最后還要感謝yyl1025老哥的答疑,問題已采納![6]
[1] https://zhuanlan.zhihu.com/p/453675608
[2] https://zhuanlan.zhihu.com/p/427488961
[3] https://baike.baidu.com/item/ASCII/309296
[4] https://baike.baidu.com/item/GB18030/3204518
[5] https://stackoverflow.com/questions/40054732
[6] https://ask.csdn.net/questions/7874166?spm=1001.2014.3001.5505
你是否還在尋找穩定的海外服務器提供商?創新互聯www.cdcxhl.cn海外機房具備T級流量清洗系統配攻擊溯源,準確流量調度確保服務器高可用性,企業級服務器適合批量采購,新人活動首月15元起,快前往官網查看詳情吧
分享名稱:字符編碼詳解及利用C++STLstring遍歷中文字符串-創新互聯
鏈接地址:http://www.js-pz168.com/article34/cohhpe.html
成都網站建設公司_創新互聯,為您提供動態網站、網站營銷、軟件開發、搜索引擎優化、網頁設計公司、App設計
聲明:本網站發布的內容(圖片、視頻和文字)以用戶投稿、用戶轉載內容為主,如果涉及侵權請盡快告知,我們將會在第一時間刪除。文章觀點不代表本網站立場,如需處理請聯系客服。電話:028-86922220;郵箱:631063699@qq.com。內容未經允許不得轉載,或轉載時需注明來源: 創新互聯

- 上海網站設計,最棒的網站設計公司 2020-11-11
- 網站設計公司:網站被降權的幾個原因 2017-02-14
- 專業網站設計公司揭秘:企業是怎么樣建網站? 2021-08-28
- 上海網站設計公司、上海網站建設公司的細節帶領你的公司走向市場 2020-11-06
- 上海網站建設公司和上海網站設計公司:Nofollow標簽是什么 2020-11-08
- 網站設計公司:網站設計要掌握的三個基本原則 2017-02-15
- 上海網站建設公司、上海網站設計公司的基本步驟是什么 2020-11-05
- 網站公司哪家好,還是上海網站設計公司、上海網站建設公司 2020-11-07
- 上海網站設計公司、上海網站建設公司在我們大學的專業學習中對我們的專業知識有多高 2020-11-06
- 小說網站的一些程序在上海網站建設公司、上海網站設計公司網站建設中的主要優勢 2020-11-08
- 網站設計公司的市場人員與客戶如何溝通 2014-01-19
- 上海網站建設公司,上海網站設計公司給你建設高質量的網站 2020-11-05